
ピープルアナリティクスのすゝめ④
はじめに
前回は、ピープルアナリティクスを成功させるためには、作業の進み方とは逆の順、アウトプット⇒分析⇒データ収集・蓄積で進めることがポイントであることを説明しました。具体的には、分析結果として何を出すのか(アウトプット)を検討し、そのためにどのような分析手法を適用するのかを検討し、その分析手法が適用可能なデータを収集する・蓄積するという発想で進めることが重要であると解説しました。
また、分析のアウトプットを検討する際には、企業の利益の向上、つまり売り上げの増加か、コストの減少に寄与するアウトプットを選択することが重要である点を説明しました。
今回からは、架空のデータを用いて、実際の分析プロセスについて説明します。分析のアウトプットとしては、社員の「離職」を選択しました。
昨今、労働力不足も相俟って、特に若手から中堅社員の離職が問題となっている企業が多くなっていると思います。社員としては自らのキャリアアップ等のポジティブな意味合いがありますが、採用する企業からすると、離職の増加は、採用や研修に投資した費用、退職に関する事務や代替要員の確保に係る費用の増加につながってしまいます。不本意な離職の防止が企業の利益に直結することは論を待たないところだと思います。
架空のデータ
ここからは、早期離職の防止を目的として、下記の架空のデータを用いて説明していきたいと思います。
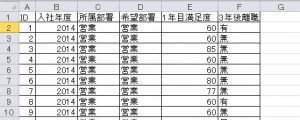
データは、2014年度入社社員と2015年度入社社員の合計88人のデータです。データの内訳としては、ID、入社年度、所属部署、希望部署、1年目満足度、3年後離職となっています。
このうち所属部署と希望部署は、配属ミスマッチが離職につながるっているのではという人事部門の仮説をもとに設定しています。実際には内定時の希望部署や所属部署は「営業一課」、「人事部採用G」、「経理部決算G」といった単位となっているのですが、「営業」、「管理」の2分類に分類し直しています。
また、「1年目満足度」は、入社1年経過後に人事部門が1年目社員と面談を行い、その際の社員満足度を人事部員が評価した結果を記録しているものです。職務満足度が離職につながるという学術的な知見があることや、離職予備軍の早期発見のための指標として今後用いることを検討するため分析データに加えたものです。
分析のステップ
データ分析の方針としては、次のように考えます。
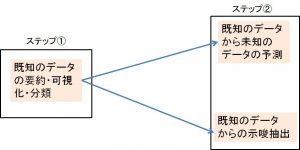
ステップ①として、まずは手元のデータをしっかり可視化したり、分類することが重要です。
その後、ステップ②として、分析の目的に応じて「既知のデータから未知のデータの予測」、「既知のデータからの示唆抽出」に進みます。
ステップ①の「既知のデータの要約・可視化・分類」を十分に行わずに、「既知のデータから未知のデータの予測」、「既知のデータからの示唆抽出」に進んでいる例も見かけますがお勧めしません。「既知のデータの要約・可視化・分類」を行うことで目的が達成できることもたくさんありますし、「既知のデータの要約・可視化・分類」を行うことで、「既知のデータから未知のデータの予測」、「既知のデータからの示唆抽出」のヒントが得られたり、効率よく進めることが出来ることが多いためです。
要約・可視化の方法
「既知のデータの要約・可視化・分類」ですが、原因と結果と、データの種類の組み合わせで考えると分りやすいです。
<原因と結果>
原因と結果の組み合わせでデータを2つ選択します。たとえば、「入社年度」によって「3年後の離職」が異なると考えるのであれば、「入社年度が」が原因、「3年後の離職」を結果と考えることが出来ます。どちらが原因でどちらが結果か分からない場合も仮にどちらかを原因と考えてきます。
<データの種類>
データの種類は大きく、分類データと数値データに分けることが出来ます。
分類データとは、「部署名」、「入社年度」、「離職の有無」といった、分類そのものが意味を持ち、大きさとしては意味を持たないデータです。残業時間を「0時間」、「10時間未満」、「10時間以上20時間未満」、、、と区分した場合も分類データに該当します。
一方で、数値データとは、今回のデータでは1~100で評価された「1年目満足度」のように数値として表現されたデータです。
以上のような原因と結果とデータの種類の組み合わせで以下のような要約・可視化の方法が有り得ます。
①原因=分類、結果=分類
原因と考えられる分類ごとに結果と考えられる分類に関して割合を算出して比較します。今回の例であれば、「所属部署の違いが離職に影響しているのでないか」という仮説に基づいて、所属部署(営業/管理)別に3年後離職割合を算出して比較することが考えられます。
②原因=分類、結果=数値
原因と考えられる分類ごとに数値の結果と考えられる結果の数値の平均値を算出して比較するのがオーソドックスな方法です。平均値以外にも、知識のある方は分散(標準偏差)、中央値といった指標を算出することが考えられます。今回の例であれば「所属で1年目満足度が異なるのではないか」と考えて、所属部署(営業/管理)別に「1年目満足度」の平均値を計算してみることが考えられます。営業と管理を分けて「1年目満足度」のヒストグラムを描いてみるのも良いでしょう。
③原因=数値、結果=分類
原因と考えられる数値を一定の区分ごとに区切って、結果と考えられる分類の割合を算出します。今回の例であれば、「入社1年経過してで満足度が低い社員はその後離職しやすい」と考え、「1年目満足度」を1~20、21~40、41~60、61~80、81~100に区分して、それぞれで離職割合を出すことが考えられます。このようにすることで、「1年目満足度」と「離職」の関係を分析することが出来ます。
④原因=数値、結果=数値
原因と結果の両方が数値の場合には、原因を横軸、結果を縦軸として散布図を描くことが最も容易かつ強力な方法です。あるいは統計の知識があれば相関係数を算出することが考えられます。今回の例では数値データは1年後の満足度だけですが、たとえば入社時の人事評価が0~10で数値評価されていれば、入社時の人事評価と「1年後の満足度」の関連を調べるといったことも可能です。
以 上
データサイエンス、職場のメンタルヘルス、健康経営、公認心理師等に関する、人事担当者様、産業保健スタッフ・心理職の方に有用な情報を配信する株式会社ベターオプションズによる無料不定期メールマガジンはこちらから登録できます。
※登録後に「申し訳ありませんが、サーバーエラーが発生したようです。また、後ほどお試しください」というメッセージが表示されることがありますが、登録は完了しておりますのでご安心ください。